 de masse
de masse  . Un système
dynamique ergodique sur X est alors une application mesurable
. Un système
dynamique ergodique sur X est alors une application mesurable
 préservant la mesure, c'est-à-dire que pour toute
partie
préservant la mesure, c'est-à-dire que pour toute
partie  (mesurable), on a
(mesurable), on a  .
L'application T n'est pas nécessairement inversible.
.
L'application T n'est pas nécessairement inversible.
Un système dynamique est une application d'un espace dans lui-même, que l'on itère. On s'intéresse à des propriétés telles que l'existence de points fixes, périodiques, la caractérisation des orbites denses, la recherche de quantités invariantes, la divergence d'orbites partant de points proches, etc. On considère généralement que l'espace a une structure supplémentaire : une structure topologique, ou bien, en théorie ergodique, une mesure de probabilité.
L'idée de la définition de l'entropie d'un système dynamique est la suivante : on considère que la position initiale du système n'est pas connue avec une précision infinie, mais que le comportement qu'on va observer en itérant le système va nous renseigner de mieux en mieux sur le point dont on est parti (par exemple, à chaque étape, on sait dire si on se trouve dans la moitié droite ou gauche de l'espace ; dans beaucoup de cas, cette information sur l'ensemble de la trajectoire permet de reconstituer le point de départ). La quantité moyenne d'information qu'on gagne à chaque itération est l'entropie du système.
On traite successivement l'entropie dans les cadres ergodique et topologique.
Soit X un espace doté d'une mesure de masse . Un système
dynamique ergodique sur X est alors une application mesurable
préservant la mesure, c'est-à-dire que pour toute
partie (mesurable), on a .
L'application T n'est pas nécessairement inversible.
Quelques exemples :
 .
.
 une matrice
une matrice  à coefficients
entiers, de déterminant
à coefficients
entiers, de déterminant  . Elle agit sur
. Elle agit sur  et l'action se
factorise sur le tore
et l'action se
factorise sur le tore  , et cette action préserve la
mesure de Lebesgue.
, et cette action préserve la
mesure de Lebesgue.
 : si
: si  , on pose
, on pose  . Cette action
préserve les mesures produits où on assigne à la lettre
. Cette action
préserve les mesures produits où on assigne à la lettre  une
probabilité
une
probabilité  , et à un mot le produit des probabilités de ses
lettres.
, et à un mot le produit des probabilités de ses
lettres.
On dit que T est ergodique si toute partie de X invariante par
T est de mesure soit  , soit
, soit  (si ce n'est pas le cas, on
décompose).
(si ce n'est pas le cas, on
décompose).
On dit que deux systèmes ergodiques  et
et
 sont mesurablement équivalents
s'il existe une bijection mesurable
sont mesurablement équivalents
s'il existe une bijection mesurable  (modulo des
ensembles de mesure nulle dans X et
(modulo des
ensembles de mesure nulle dans X et  ) qui envoie la mesure
) qui envoie la mesure  sur
sur  et qui envoie l'action sur l'action, i.e.
et qui envoie l'action sur l'action, i.e.
 .
.
Un des principaux buts de la théorie est d'essayer de classer les systèmes ergodiques à équivalence près.
Von Neumann a défini toute une classe d'invariants de systèmes ergodiques : les invariants spectraux. On peut évidemment se demander si ces invariants suffisent à déterminer la dynamique à équivalence près. C'étaient les seuls invariants connus jusqu'à l'introduction de l'entropie ergodique par Kolmogorov.
L'idée est de faire agir T sur des espaces de fonctions sur X en envoyant
une fonction f sur  . En particulier, ceci définit un
opérateur
. En particulier, ceci définit un
opérateur  , et comme T conserve la
mesure, cet opérateur est une isométrie de
, et comme T conserve la
mesure, cet opérateur est une isométrie de  .
.
Les propriétés de cet opérateur permettent de capturer une partie du
comportement du système. Par exemple, le fait que T soit ergodique est
équivalent au fait que  . Le fait que T soit
mélangeant (i.e. pour toutes parties
. Le fait que T soit
mélangeant (i.e. pour toutes parties  , on a
, on a  ) est équivalent au fait que pour toutes
fonctions
) est équivalent au fait que pour toutes
fonctions  , on a
, on a  .
.
Dans le cas d'une matrice de 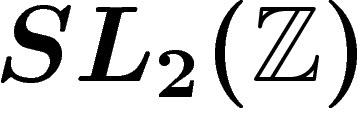 agissant sur le tore
agissant sur le tore  , la base de Fourier de
, la base de Fourier de  permet
de calculer explicitement l'opérateur. Par exemple si
permet
de calculer explicitement l'opérateur. Par exemple si  , la
transformation induite est ergodique si et seulement si le spectre de A
ne contient pas de racine de l'unité, ou encore si et seulement si toutes
les orbites de la transposée
, la
transformation induite est ergodique si et seulement si le spectre de A
ne contient pas de racine de l'unité, ou encore si et seulement si toutes
les orbites de la transposée  agissant sur
agissant sur  sont infinies.
On voit alors sur la base de Fourier, dans cette situation, que toutes
les matrices A ergodiques seront spectralement équivalentes. Sont-elles
mesurablement équivalentes ?
sont infinies.
On voit alors sur la base de Fourier, dans cette situation, que toutes
les matrices A ergodiques seront spectralement équivalentes. Sont-elles
mesurablement équivalentes ?
Pour  valeur propre de
valeur propre de  , on note
, on note  .
.
Une application ergodique T vérifie alors les propriétés suivantes. Si
 , alors le module de f est constant. De plus, pour tout
, alors le module de f est constant. De plus, pour tout
 on a
on a  . Enfin, l'ensemble des valeurs propres
de T est un sous-groupe dénombrable du cercle unité de
. Enfin, l'ensemble des valeurs propres
de T est un sous-groupe dénombrable du cercle unité de  .
(De plus, on peut montrer que tout sous-groupe dénombrable du cercle peut
être obtenu ainsi.)
.
(De plus, on peut montrer que tout sous-groupe dénombrable du cercle peut
être obtenu ainsi.)
On dit que T est à spectre purement atomique si les  engendrent (au sens
engendrent (au sens  ) l'espace
) l'espace  .
.
Von Neumann a démontré que pour des opérateurs à spectre purement atomique, la dynamique est caractérisée par les invariants spectraux :
À ce stade on ne sait toujours pas si les actions linéaires sur le tore sont mesurablement équivalentes. L'entropie ergodique permet de répondre à cette question.
Pour définir l'entropie ergodique, on se donne une partition
 (non triviale) de X. On regarde dans quelle partie de la
partition tombent les itérés
(non triviale) de X. On regarde dans quelle partie de la
partition tombent les itérés  d'un point de départ x. L'idée est
que cette suite de parties fournit de l'information sur le point x ;
l'entropie est alors la quantité d'information moyenne que chaque
itération de T apporte.
d'un point de départ x. L'idée est
que cette suite de parties fournit de l'information sur le point x ;
l'entropie est alors la quantité d'information moyenne que chaque
itération de T apporte.
La suite des parties dans lesquelles tombe  constitue donc une
sorte de code de x.
constitue donc une
sorte de code de x.
Soit  l'ensemble des points
l'ensemble des points  tels que pour tout
tels que pour tout
 , les points
, les points  et
et  sont dans la même partie de la
partition
sont dans la même partie de la
partition  .
.
On dit que T est fortement ergodique si tous les itérés  sont ergodiques (une application ergodique n'est pas
nécessairement fortement ergodique).
sont ergodiques (une application ergodique n'est pas
nécessairement fortement ergodique).
On montre alors facilement que si T est fortement ergodique, alors pour
tout x, la mesure  est nulle. Autrement
dit, le codage code bien. En effet, soit
est nulle. Autrement
dit, le codage code bien. En effet, soit  et
supposons
et
supposons  . Par le théorème de récurrence de Poincaré, il
existe un n tel que
. Par le théorème de récurrence de Poincaré, il
existe un n tel que  . Soit donc
. Soit donc  , alors le code de y est périodique de période n. En
particulier, le code de x est périodique. Donc
, alors le code de y est périodique de période n. En
particulier, le code de x est périodique. Donc  .
Comme T conserve la mesure, on a donc
.
Comme T conserve la mesure, on a donc  ce qui contredit
l'ergodicité de
ce qui contredit
l'ergodicité de  .
.
On voit donc que  tend vers
tend vers  . En fait cette
quantité tend exponentiellement vite vers
. En fait cette
quantité tend exponentiellement vite vers  , et l'exposant est
précisément lié à l'entropie ergodique de T. On sait par la théorie de
l'information que donner le code de x dans
la partition jusqu'à l'étape n, c'est donner une quantité d'information
, et l'exposant est
précisément lié à l'entropie ergodique de T. On sait par la théorie de
l'information que donner le code de x dans
la partition jusqu'à l'étape n, c'est donner une quantité d'information  . Ceci est précisé par le théorème-définition
suivant, énoncé d'abord par Shannon :
. Ceci est précisé par le théorème-définition
suivant, énoncé d'abord par Shannon :
 une application préservant la mesure
une application préservant la mesure  . Soit
. Soit
 une partition de X telle que
une partition de X telle que
![\[
-\sum_{P\in \mathcal{P}} \mu(P)\log \mu(P)<\infty
\]](entropie235.png)
![\[
h(T,\mathcal{P},x)=-\lim_{n\rightarrow\infty} \frac1n\log
\mu(\mathcal{P}_n(x))
\]](entropie236.png)
 -presque tout x, et cette quantité, en tant que
fonction de x, converge dans
-presque tout x, et cette quantité, en tant que
fonction de x, converge dans  vers une fonction T-invariante.
vers une fonction T-invariante.
En particulier, si T est ergodique, l'entropie ne dépend pas de x.
Sinon, on moyenne en posant  . Ensuite, on remarque que l'entropie augmente
lorsqu'on raffine la partition, on pose donc :
. Ensuite, on remarque que l'entropie augmente
lorsqu'on raffine la partition, on pose donc :
![\[
h(T)=\sup_{\mathcal{P}}h(T,\mathcal{P})
\]](entropie240.png)
Par construction, c'est un invariant d'équivalence mesurable.
Pour  agissant sur le tore, on peut montrer que cette
entropie est égale au log du module de la plus grande valeur propre. En
particulier, toutes les matrices ergodiques ne sont pas mesurablement
équivalentes.
agissant sur le tore, on peut montrer que cette
entropie est égale au log du module de la plus grande valeur propre. En
particulier, toutes les matrices ergodiques ne sont pas mesurablement
équivalentes.
Pour le décalage de Bernoulli, sur un alphabet  ,
considérons la partition
,
considérons la partition  où
où
 . On peut raffiner cette partition par
le décalage, cela revient à fixer les n premières lettres, on obtient
ainsi des partitions arbitrairement fines. L'entropie de ces partitions
se calcule facilement : on a
. On peut raffiner cette partition par
le décalage, cela revient à fixer les n premières lettres, on obtient
ainsi des partitions arbitrairement fines. L'entropie de ces partitions
se calcule facilement : on a  . Si
. Si  est la probabilité
d'occurrence de la lettre k, la mesure de l'ensemble
est la probabilité
d'occurrence de la lettre k, la mesure de l'ensemble  vaut alors simplement
vaut alors simplement  . On a donc
. On a donc  . Or, pour presque
tout x, la proportion des
. Or, pour presque
tout x, la proportion des  qui sont égaux à la
lettre
qui sont égaux à la
lettre  est, d'après la loi des grands nombres,
est, d'après la loi des grands nombres,  . La quantité
. La quantité
 vaut donc, pour
vaut donc, pour  -presque tout x :
-presque tout x :
![\[
-\sum p_k \log p_k
\]](entropie255.png)
 . On
retrouve donc la vieille formule de Boltzmann...
. On
retrouve donc la vieille formule de Boltzmann...
En fait, un théorème difficile d'Ornstein affirme que deux décalages de
Bernoulli (même sur des alphabets n'ayant pas le même nombre de
lettres !) sont mesurablement équivalents si et seulement s'ils ont la
même entropie. Ce théorème, combiné à un autre de Katznelson qui affirme
que toute application de  agissant sur le tore est
mesurablement équivalente à un décalage de Bernoulli (indexé par
agissant sur le tore est
mesurablement équivalente à un décalage de Bernoulli (indexé par  ),
permet de traiter aussi le cas du tore.
),
permet de traiter aussi le cas du tore.
On se place désormais dans un cadre métrique plutôt que mesuré. Soit donc
 un espace métrique compact, et
un espace métrique compact, et  une application
continue. La théorie de l'entropie topologique que l'on développe alors
est due à Adler, Konheim, McAndrew.
une application
continue. La théorie de l'entropie topologique que l'on développe alors
est due à Adler, Konheim, McAndrew.
L'idée est là encore qu'on ne peut séparer les points qu'avec une certaine précision, et qu'on espère que l'observation des trajectoires des points par f nous renseignera sur leur position initiale.
Soit donc  . On dit que deux points
. On dit que deux points  sont
sont  -séparés
si
-séparés
si  . On dit que x et y sont
. On dit que x et y sont  -séparés en temps n
s'il existe un
-séparés en temps n
s'il existe un  tel que
tel que  . Ceci amène
naturellement à définir la distance
. Ceci amène
naturellement à définir la distance
![\[
\dist_n(x,y)=\max_{0\leq k\leq n} \dist(f^kx,f^ky)
\]](entropie268.png)
Plus n est grand, plus on sépare de points. Soit  le nombre
maximum de points d'une famille de points deux à deux
le nombre
maximum de points d'une famille de points deux à deux  -séparés.
Combinatoirement, identifier l'un de ces points est donner une
information
-séparés.
Combinatoirement, identifier l'un de ces points est donner une
information  .
On définit l'entropie topologique de f par
.
On définit l'entropie topologique de f par
![\[
h_{top}(f,\eps)=\vlimsup_{n\rightarrow \infty}\frac1n \log H(n,\eps)
\]](entropie272.png)
![\[
h_{top}(f)=\lim_{\eps\rightarrow 0} h_{top}(f,\eps)
\]](entropie273.png)
 croît quand
croît quand  décroît, cette limite
est donc bien définie.)
décroît, cette limite
est donc bien définie.)
On aurait pu donner une variante de cette définition en posant pour
 le nombre minimal de boules de rayon
le nombre minimal de boules de rayon  pour
pour  recouvrant tout X. On trouve la même entropie.
recouvrant tout X. On trouve la même entropie.
Une autre manière de voir est de considérer le graphe
 et de compter le nombre
de pavés de côté
et de compter le nombre
de pavés de côté  nécessaires pour le recouvrir.
nécessaires pour le recouvrir.
Comme X est compact, deux métriques quelconques donnant la même topologie sont uniformément équivalentes. Cela implique que l'entropie définie ci-dessus ne dépend pas de la métrique choisie, d'où son qualificatif de topologique.
L'entropie topologique est liée à l'entropie ergodique définie plus haut :
![\[
h_{top}(f)=\sup\{h(f,\mu), \mu\text{ mesure de probabilité }f\text{-invariante
sur }X\}
\]](entropie281.png)
On peut de plus montrer que si f est un
difféomorphisme  d'une variété, ce sup est atteint.
d'une variété, ce sup est atteint.
Premier exemple : l'entropie d'une rotation du cercle est nulle, comme celle de toute isométrie.
L'entropie de l'application du cercle unité de  définie par
définie par  est égale à
est égale à  : en effet on a
: en effet on a  , on sépare
deux fois mieux les points à chaque itération. De manière plus générale,
l'entropie de
, on sépare
deux fois mieux les points à chaque itération. De manière plus générale,
l'entropie de  sur le cercle est égale à
sur le cercle est égale à  .
.
Soit la matrice  agissant sur le tore
agissant sur le tore
 . On a une valeur propre dilatante
. On a une valeur propre dilatante  ,
et une étude locale montre que l'entropie est égale au log de cette
valeur.
,
et une étude locale montre que l'entropie est égale au log de cette
valeur.
De manière générale, si un système dynamique (ou l'un de ses itérés) possède une figure topologiquement équivalente à un « fer à cheval », c'est-à-dire un carré dont l'image par f l'intersecte deux fois (dans la bonne direction), alors l'entropie topologique sera strictement positive.

En effet dans cette situation, on a un ensemble limite composé d'une infinité de bandes dans le carré, et spécifier un point sur une bande demande de spécifier, pour chaque étape, si on choisit la partie haute ou la partie basse.
Inversement, un théorème de Katok affirme que si f est un
difféomorphisme  d'une surface compacte, d'entropie strictement
positive, alors f ou l'un de ses itérés possède un fer à cheval.
d'une surface compacte, d'entropie strictement
positive, alors f ou l'un de ses itérés possède un fer à cheval.
Dans cette situation, on peut définir d'autres invariants à l'aide de l'idée d'entropie. L'un d'eux est l'entropie algébrique.
Soient X une variété compacte lisse et f une application
 . Elle induit un morphisme sur le groupe fondamental de
X, soit
. Elle induit un morphisme sur le groupe fondamental de
X, soit  . (Mettons pour simplifier
qu'il existe un point périodique, qu'on prend comme point-base du
. (Mettons pour simplifier
qu'il existe un point périodique, qu'on prend comme point-base du
 .)
.)
Le groupe fondamental  est engendré par une partie génératrice
est engendré par une partie génératrice
 (on prend S symétrique, c'est-à-dire que S
contient les inverses de ses éléments), ces éléments vérifiant certaines
relations. Alors, tout élément du
(on prend S symétrique, c'est-à-dire que S
contient les inverses de ses éléments), ces éléments vérifiant certaines
relations. Alors, tout élément du  peut être écrit comme un
produit d'éléments de S. On définit la longueur
peut être écrit comme un
produit d'éléments de S. On définit la longueur  d'un élément
d'un élément
 comme le nombre minimal d'éléments de S qu'il faut pour
l'écrire.
comme le nombre minimal d'éléments de S qu'il faut pour
l'écrire.
On pose alors
![\[
h_{\pi_1}(f)=\vlimsup_{n\rightarrow\infty} \frac1n\log \max_{1\leq i\leq
k} \ell(f_\ast^n a_k)
\]](entropie302.png)
L'entropie ne dépend pas du système S de générateurs choisi. Cela se
voit en regardant la longueur des éléments d'une nouvelle partie
génératrice par rapport à l'ancienne, et en utilisant la relation
 .
.
De même, cette entropie est invariante par automorphisme intérieur du
 (conjugaison par un certain élément), ce qui implique que cette
définition ne dépend pas du point-base choisi.
(conjugaison par un certain élément), ce qui implique que cette
définition ne dépend pas du point-base choisi.
Un théorème de Manning précise le rapport entre entropie topologique et entropie algébrique :
 sur une variété lisse. Alors
sur une variété lisse. Alors
![\[
h_{top}(f)\geq h_{\pi_1}(f)
\]](entropie306.png)
A priori, l'action sur le groupe fondamental ne capture donc qu'une partie de la complexité de la dynamique.
On peut travailler sur l'homologie comme sur le groupe fondamental.
L'application f définit un opérateur sur l'homologie  . L'analogue de l'entropie
algébrique est alors le log du rayon spectral
. L'analogue de l'entropie
algébrique est alors le log du rayon spectral
 (comparer avec le cas d'une
application linéaire sur le tore), et on a un analogue, dû à Yomdin, du
théorème de Manning :
(comparer avec le cas d'une
application linéaire sur le tore), et on a un analogue, dû à Yomdin, du
théorème de Manning :
 un difféomorphisme
un difféomorphisme  d'une variété
lisse, et soit
d'une variété
lisse, et soit  le rayon spectral de
le rayon spectral de  , alors
, alors
![\[
h_{top}(f)\geq \log \rho = \lim \frac1n \log \norm{f_\ast^n}
\]](entropie313.png)
Si X est de dimension n, on peut simplement restreindre  à
l'homologie en degré n de X, soit
à
l'homologie en degré n de X, soit  . Le rayon
spectral correspondant est alors simplement le degré topologique d de
f, et on a le théorème suivant :
. Le rayon
spectral correspondant est alors simplement le degré topologique d de
f, et on a le théorème suivant :
 une application
une application  sur une variété lisse, de
degré d. Alors
sur une variété lisse, de
degré d. Alors
![\[
h_{top}(f)\geq \log d
\]](entropie318.png)
Attention, l'hypothèse de régularité  est nécessaire ! Par exemple
sur
est nécessaire ! Par exemple
sur  , si on considère l'application donnée en coordonnées polaires
par
, si on considère l'application donnée en coordonnées polaires
par  , son degré est
, son degré est
 , mais toutes les orbites tendent vers
, mais toutes les orbites tendent vers  donc l'entropie est nulle.
Bien sûr, cette application n'est pas
donc l'entropie est nulle.
Bien sûr, cette application n'est pas  en
en  ...
...
L'idée de la preuve est la suivante : on prend un point et on regarde
l'ensemble de ses préimages par f au temps n, il y en a  pour un
point typique. L'hypothèse de régularité
pour un
point typique. L'hypothèse de régularité  intervient pour dire que
tous ces points sont bien séparés (par exemple s'il n'y a pas de point
critique, le jacobien est uniformément minoré).
intervient pour dire que
tous ces points sont bien séparés (par exemple s'il n'y a pas de point
critique, le jacobien est uniformément minoré).
L'entropie algébrique ne capture donc en général qu'une partie de la complexité d'un système. On peut se demander dans quels cas on a égalité.
Soit f une application polynomiale du plan complexe complété par un
point à l'infini :  . Par
exemple,
. Par
exemple,  ... Soit d le degré du polynôme, c'est aussi
le degré topologique de f et on sait donc que
... Soit d le degré du polynôme, c'est aussi
le degré topologique de f et on sait donc que  .
Un théorème de Gromov pose l'égalité :
.
Un théorème de Gromov pose l'égalité :
 dans lui-même,
de degré d. Alors
dans lui-même,
de degré d. Alors
![\[
h_{top}(f)=\log d
\]](entropie332.png)
L'idée de la preuve est de regarder le graphe
 . On cherche à évaluer le nombre
. On cherche à évaluer le nombre
 de pavés de taille
de pavés de taille  qu'il faut pour le recouvrir.
L'aire de
qu'il faut pour le recouvrir.
L'aire de  est supérieure à ce nombre fois la « densité
minimale » de
est supérieure à ce nombre fois la « densité
minimale » de  dans un pavé de taille
dans un pavé de taille  , c'est-à-dire la
plus petite surface qu'on peut y mettre. Or l'aire de
, c'est-à-dire la
plus petite surface qu'on peut y mettre. Or l'aire de  est
calculable par des moyens homologiques, et la densité minimale se trouve
être négligeable, ce qui permet d'arriver au résultat.
est
calculable par des moyens homologiques, et la densité minimale se trouve
être négligeable, ce qui permet d'arriver au résultat.
Ce théorème se généralise à toute variété kählerienne compacte.
Là encore, le sujet est loin d'être clos.